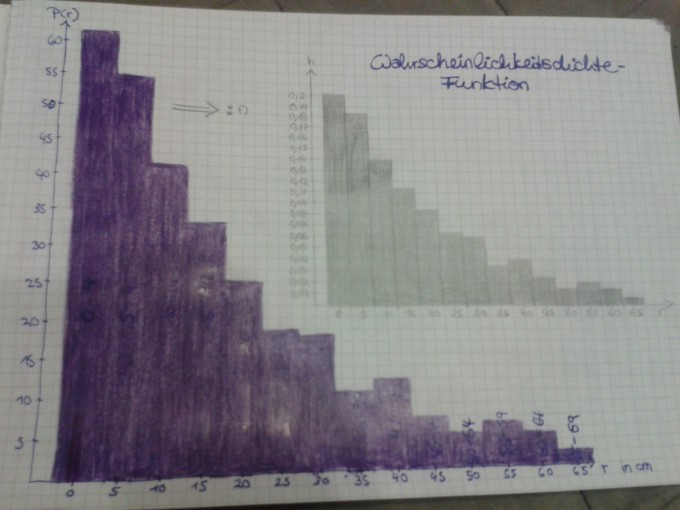
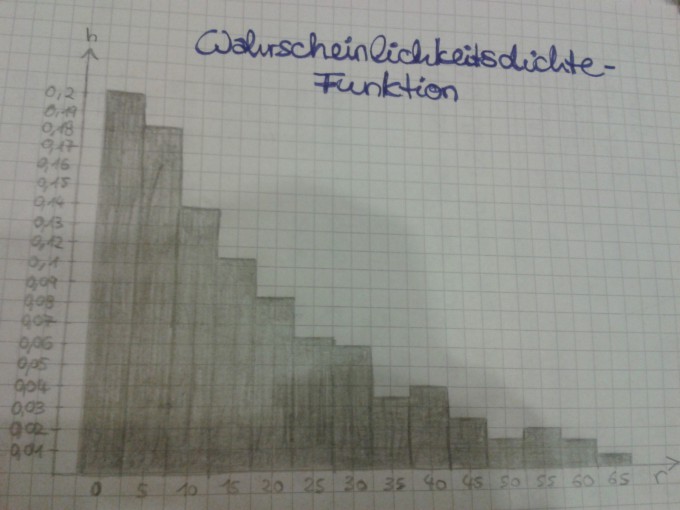
Ich habe für mein Abitur ein Matheprojekt zu machen. Aufgabenstellungen:
Projektarbeit zur Stochastik
Bei einem Spiel werden Münzen gegen eine Wand geworfen und der Abstand der Münze zur Wand gemessen, wenn die Münze liegen bleibt. Gewinner ist, wessen Münze am nächsten an der Wand liegt. Die gemessenen Abstände einer Spielserie finden Sie in der Tabelle unten.
a) Bestimmen Sie die Wahrscheinlichkeit dafir, dass der Abstand der Münze zur Wand kleiner \( 20 \mathrm{~cm} \) ist.
b) Bestimmen Sie die Wahrscheinlichkeit dafür, dass die Münze in einem Abstand von \( 10 \mathrm{~cm} \) bis \( 20 \mathrm{~cm} \) liegen bleibt.
c) Stellen Sie eine zu den Daten passende Wahrscheinlichkeitsdichtefunktion auf.
Tipp: Es ist einfacher, wenn Sie als Maßeinheit \( [d m] \) benutzen, prinzipiell können Sie aber jede Längeneinheit nutzen.
d) Beweisen Sie, dass es sich bei der von Ihnen gefundenen Funktion um eine Wahrscheinlichkeitsdichtefunktion handelt.
e) Diskutieren Sie, wie gut Ihre Wahrscheinlichkeitsdichtefunktion zu den gegebenen Daten passt.
Ansatz/Problem:
a) und b): Hier wäre ich euch dankbar, wenn ihr einfach über meine Rechnung drüber guckt und mich auf eventuell Fehler hinweist.
c): Ich bin mir nicht sicher ob das Erstellen eines Histogramms als Aufstellen einer Wahrscheinlichkeitsdichtefunktion reicht oder ob ich hier eine Funktion im Sinne f(x)=? herausfinden muss. Wenn ja, wie? Durch eine Exponentialfunktion annähern? Wenn ja, wie sehe dann die Rechnung (analytisch) aus? Oder die Funktion stückweise definieren? Da sie ja nicht konstant fällt?
d): Die Kriterien einer Wahrscheinlichkeitsdichtefunktion sind doch x= >0 und die Fläche unter der Funktion = 1. ?! Beide Kriterien sind erfüllt. Ist damit bewiesen, dass es sich um eine Wahrscheinlichkeitsdichtefunktion handelt? Oder wie muss ich hier weiter argumentieren?
e): An dieser scheitere ich. Dafür brauche ich doch nun wirklich eine Funktion im Sinne f(x)=? oder? Und wieso sollte meine Funktion nicht zu den Daten passen, sie ist doch daraus entstanden? Oder ist damit wirklich eine näherungsweise Funktion gemeint?